Hasta ahora hemos visto cómo serializar nuestros datos y guardarlos en ficheros de nuestro disco. Si tenemos una gran cantidad de datos sería bueno que en vez de leer todos los datos y tratarlos en nuestra aplicación para seleccionar el que de verdad necesito (a lo mejor un cliente de entre millones) sería bueno usar un Sistema Gestor de Base de Datos (SGBD), que aparte de ofrecerme las típicas operaciones SQL puedo consumirlo como un servicio que atienda muchas peticiones a la vez. En cualquier caso, está claro que no vale simplemente con guardar en un fichero unos cuantos datos y que Spring tiene su solución.
Me voy a centrar en las Bases de Datos Relacionales ya que JPA está pensado para estas (quedan fuera del contenido las BD NoSQL)
¿Qué es JPA?
JPA es el acrónimo de Java Persistence API lo cual deja bastante claro de qué se ocupa: Es una API para Persistencia en Java. Para saber cómo utilizarlo hay un wikibook que explica bastante clara y concisamente su uso proporcionando ejemplos en las dos formas distintas que hay de definir cómo ejecutar la persistencia de nuestros datos.JPA es la definición de una API pero no una implementación. De la misma forma que vimos en la entrada de logging, usamos una API que nos proporciona una fachada frente a sus implementaciones y de esta forma es sencillo cambiar la implementación usada por la aplicación. Existen varias implementaciones:
- Hibernate: la más famosa y la que vamos a estar usando en el curso
- EclipseLink: Proyecto Open Source de la Fundación Eclipse
- DataNucleus: También Open Source
- Se pueden ver más en el wikibook
Lo normal es que este tipo de herramientas proporcionen un mapeo entre objetos de aplicación y registros en SGBD relacional. De esta forma la aplicación es capaz de volcar nuestros datos en memoria a una BD y viceversa. Esto se conoce como Object-Relacional Mapping (ORM) y veremos su uso más adelante.
El sentido de tener JPA, ORM, Hibernate, etc... es que hay también mucho código boilerplate y es muy laborioso de implementar, probar y repetitivo. Sirva como ejemplo ese snipet básico con JDBC de una implementación para el supuesto con el que vamos a trabajar: tiene cientos de líneas de código, hace bastante poco y está muy ligado a un SGBD concreto.
Usando JPA vamos a persistir nuestros datos en cualquier SGBD con muy poco código, de manera fiable y con una facilidad increíble de cambiar de SGBD sin tener que modificar el código. Para guardar una entidad podremos hacerlo simplemente con dos anotaciones sobre ella y declarar una interface que extienda otra con una anotación sobre ella. Voy a usar un POJO simple para una clase
Usuario que pondré, para simplificar este ejemplo, en el paquete es.lanyu.usuarios.repositorios pero no es obligatorio:@Entity
public class Usuario {
@Id
// @GeneratedValue
// int id;
String nombre;
String correo;
}@Entity y @Id definen que esta clase es una entidad y que su clave principal es el nombre de usuario.Para guardar la entidad Usuario hay que crear un Repositorio que tendrá las operaciones CRUD típicas. Será mi interface
UsuarioDAO y lo pongo en el mismo paquete que Usuario:@Repository
public interface UsuarioDAO extends JpaRepository {} Si hacemos memoria, cuando vimos
@Component había tres especializaciones de ella, aquí estamos usando una de ellas: @Repository.Al marcar esta interface con esa anotación la estamos haciendo autodetectable y puede ser escaneada para ser añadida como un bean.
Si ejecutamos el código en este punto no hará nada, de hecho ni siquiera será escaneado. Nos falta el encargado de hacer que todo esto funcione, que sepa con que BD debe conectar, las credenciales para hacerlo, la implementación a usar y otras configuraciones necesarias. El responsable de todo esto en JPA se llama EntityManager.
Hay varias formas de crearlo. Nosotros vamos a usar XML y voy a incluir también dónde están nuestros repositorios de JPA. Si se nos pasa el momento de susto al ver un XML con muchas cosas que no entendemos y nos centramos en lo importante, veremos que es prácticamente un copy & paste de este snipet.
NOTA: Estoy usando la capacidad que tenemos de configurar con propiedades el XML para mejorar la reutilización y simplificarlo, pero podría estar escrito el valor directamente.
Sólo tenemos que establecer nuestras propiedades para decir dónde están nuestros repositorios y nuestras entidades:
es.lanyu.entities-package=es.lanyu.usuarios.repositorios
es.lanyu.jpa-package=${es.lanyu.entities-package}- Para la ubicación de los repositorios JPA con @EnableJpaRepositories
- Para la ubicación de nuestras entidades a escanear con @EntityScan
main así:public static void main(String[] args) {
ConfigurableApplicationContext context =
SpringApplication.run(DatosdeportivosapiApplication.class, args);
UsuarioDAO usuarioDAO = context.getBean(UsuarioDAO.class);
usuarioDAO.save(generaUsuario());
List<Usuario> usuarios = usuarioDAO.findAll();
usuarios.stream().map(Usuario::toString).forEach(log::info);
context.close();
}
static Usuario generaUsuario() {
int numero = 10000;
String usuario = "user" + ThreadLocalRandom.current().nextInt(numero, numero*20);
return new Usuario(usuario, usuario + "@mail.com");
}¿Qué operaciones tiene mi repositorio?
Tiene las que se pueden esperar de un CRUD. Usando el asistente de contenido no hacemos una idea. Lo bueno de es que JPA tiene una sintaxis para el nombre de sus métodos que implica un mapeo a una sentencia SQL sin tener que implementarla. El siguiente diagrama lo describe: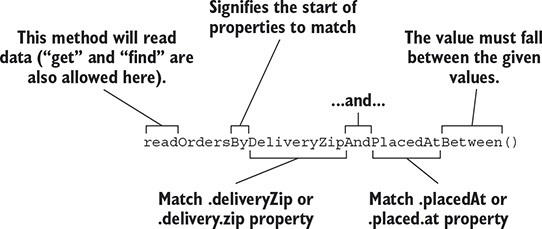
Fuente: Libro Spring in Action
Podemos ver las palabras clave y posibilidades de esta sintaxis en la documentación.
En nuestro caso vamos a recuperar todos los usuarios que contengan un texto que digamos en su correo:
List<Usuario> findByCorreoContaining(String txt);List<Usuario> usuarios = usuarioDAO.findByCorreoContaining("5");Puedes ver el código hasta este punto en su repositorio.
Lo siguiente que veremos es cómo hacer ese mapeo ORM sobre entidades a las que no tenemos acceso al código.







Esta entrada está padre!
ResponderEliminar